
ByteDance Astra: Breaking Navigation Bottlenecks for General-Purpose Mobile Robots
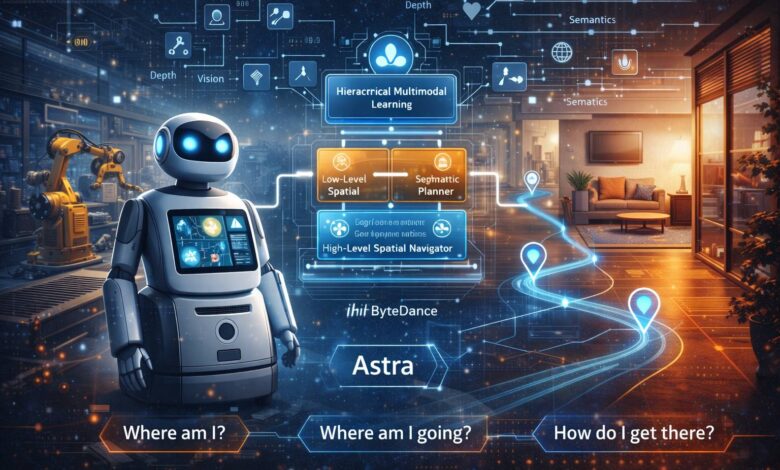
The surge of robots into sectors ranging from industrial manufacturing to daily life has placed an intense spotlight on a foundational challenge: advanced navigation. Current systems often struggle in the face of complex, diverse indoor environments, revealing the acute limitations of traditional modular approaches. To address the core navigation questions of “Where am I?”, “Where am I going?”, and “How do I get there?”, ByteDance has unveiled Astra, an innovative dual-model architecture designed to enable general-purpose mobile robots to conquer these bottlenecks. Detailed in the research paper “Astra: Toward General-Purpose Mobile Robots via Hierarchical Multimodal Learning,” this architecture promises to redefine robot navigation in intricate indoor spaces.
Reinventing the Navigation Stack
Traditional robot navigation relies on a complex assembly of multiple, often rule-based, smaller modules. These modules are tasked with three key functions:
-
Target Localization: Interpreting commands (natural language or images) to identify a destination on a map.
-
Self-Localization: Pinpointing the robot’s precise position within that map. This is especially challenging in repetitive environments like warehouses, where traditional methods often necessitate artificial landmarks like QR codes.
-
Path Planning: Generating a global route (rough path) and a local plan for real-time obstacle avoidance.
While the rise of foundation models has suggested a path toward integrating these tasks, determining the optimal number of models and their effective synthesis remained a critical open question. Astra answers this with a hierarchical, System 1/System 2-inspired architecture, utilizing two distinct sub-models to process tasks based on their frequency.
System Architecture: A Functional Split
The cornerstone of Astra’s innovation is the strategic division of navigation tasks into two primary components: Astra-Global and Astra-Local.
1. Astra-Global: The High-Level Brain for Strategic Localization
Astra-Global functions as a Multimodal Large Language Model (MLLM) and acts as the intelligent core, handling critical low-frequency tasks: self-localization and target localization. Its core strength lies in its ability to process visual and linguistic inputs against a hybrid topological-semantic graph, enabling it to derive precise global positions from a simple query image or text prompt.
This capability is built upon a robust offline mapping process. The system temporal downsamples video and uses Structure from Motion (SfM) to estimate 6-Degrees-of-Freedom (DoF) camera poses, which serve as graph nodes. Undirected edges establish connectivity, and semantic landmark information is extracted and stored, enriching the map with deep semantic understanding. Landmarks are also linked to multiple nodes via co-visibility, creating a highly resilient contextual web.
In operation, Astra-Global utilizes a meticulous, two-stage process for visual-language localization:
-
Coarse Stage: The model analyzes the input and prompt, detects landmarks, matches them against the pre-built semantic map, and filters candidates based on visual consistency.
-
Fine Stage: The query image and coarse output are used to sample reference nodes from the offline map. The model compares visual and positional information to output a direct, predicted 6-DoF pose.
For language-based target commands (e.g., “find the resting area”), the model interprets the natural language, identifies relevant landmarks via their functional descriptions, and leverages node association to locate the target image and pose.
Training for Generalization
Astra-Global’s backbone is Qwen2.5-VL. The training methodology combined Supervised Fine-Tuning (SFT) with Group Relative Policy Optimization (GRPO). While SFT provided foundational task training, GRPO used a rule-based reward function (format, landmark extraction, map matching, etc.) to dramatically boost zero-shot generalization. Experiments confirmed this approach, with GRPO enabling Astra-Global to achieve an astounding 99.9% localization accuracy in unseen home environments, vastly outperforming SFT-only methods.
2. Astra-Local: The Agile Assistant for Real-Time Execution
Astra-Local acts as the intelligent assistant, managing the high-frequency tasks of local path planning and odometry estimation. This multi-task network processes sensor data to efficiently generate executable paths and estimate relative motion.
The architecture of Astra-Local includes three core components:
-
4D Spatio-Temporal Encoder: Replacing traditional mobile stack perception, this component uses a 3D spatial encoder (processing omnidirectional images via ViT and Lift-Splat-Shoot) to convert 2D features into 3D voxel features. A 4D encoder then uses past features and future timestamps to predict future voxel features, creating a continuous environmental representation.
-
Planning Head: This head uses pre-trained 4D features, robot speed, and task information to generate executable trajectories via Transformer-based flow matching. A critical innovation here is the incorporation of a masked ESDF (Euclidean Signed Distance Field) loss. By calculating the ESDF of a 3D occupancy map and applying a 2D ground truth trajectory mask, this loss significantly mitigates collision risks, enabling superior performance in out-of-distribution (OOD) scenarios.
-
Odometry Head: This component predicts the robot’s relative pose by fusing data from the 4D features, IMU, and wheel sensors. It utilizes a Transformer model to tokenize and fuse different modalities, which experiments showed dramatically improves rotational accuracy and reduces overall trajectory error.
Moving Beyond Modular Rigidity
The introduction of Astra is a significant step forward, signaling a shift away from the “brittle integration” that has long plagued robotics. Traditional navigation stacks are often collections of delicate, rule-based modules; a failure in perception cascades into a failure in planning. Astra’s dual-model architecture provides a crucial layer of robustness by moving towards integrated, learned end-to-end systems.
This “learned semantic understanding” approach is what allows Astra-Global to achieve 99.9% accuracy in unseen environments. Traditional Visual Place Recognition (VPR) systems fail when camera angles change or scenes are visually similar. Astra-Global’s ability to leverage a semantic map—to “know” what a specific room number or functional landmark is, regardless of the viewpoint—provides the high-level reasoning needed for true autonomy.
Similarly, Astra-Local’s use of a masked ESDF loss directly addresses one of the major pain points of learned planning policies: the collision rate in unfamiliar territory. By forcing the network to respect the geometric reality of a 3D occupancy map, ByteDance has bridged the gap between pure end-to-end learning and established safety principles.
The future of mobile robotics will depend on systems that can move seamlessly between high-level reasoning (“where am I going?”) and low-level execution (“how do I dodge this chair?”). Astra is not just a dual-model system; it is a blueprint for a more coherent and resilient robot brain, promising a new era of general-purpose mobile robots that can finally navigate the complexity of the human world.


